

Open Creative Studio features five independent image generation pipelines, each with its own configuration:
- FLUX 1, which supports Black Forest Labs’ FLUX.1 Dev and its fine-tuned versions (like FLUX.1 Dev Krea).
- Stable Diffusion 3, which supports Stability AI’s Stable Diffusion 3.5 Large.
- Stable Diffusion XL, which supports Stability AI’s SDXL and its fine-tuned versions (like Juggernaut XL).
- Stable Diffusion 1.5, which supports Stability AI’s Stable Diffusion 1.5 and its fine-tuned versions (like Realistic Vision 6.0).
- Qwen Image 1, which supports Alibaba’s Qwen Image.
- GPT-Image-1 by OpenAI
These pipelines can be activated or deactivated independently, and each one can be configured with its own set of parameters.
This means that, given a prompt, you could configure Open Creative Studio to always generate both a FLUX.1 Dev and an SDXL image.
It also means that, without any manual reconfiguration, you could configure Open Creative Studio to generate an image with SD 1.5 and immediately repaint it with FLUX.1 Dev.
The pipelines dedicated to open-access, local image generation models feature the following customizable building blocks:
These pipelines include additional building blocks, like the log function, but they don’t contain any parameters that you should modify.
The pipelines dedicated to commercial, hosted image generation models, like OpenAI GPT-Image-1, only feature the image configurator.
NOTICE: Unless specified, any Open Creative Studio image generation pipeline supports both the base model and its many fine-tuned variants.
For example, the FLUX.1 pipeline supports both FLUX.1 Dev and FLUX.1 Krea Dev.
Configurators
The Configurator function in each image generation pipeline is one of the most complex and critical parts of Open Creative Studio.
Here, you can modify parameters like the model being used, the diffusion steps, the type of sampler and scheduler, and much more.
For example, if the image generation is too slow for your taste, and you are happy compromising on image quality, you can reduce the number of steps from 50 (default) to 25 or less.
WARNING: You should not modify any of these parameters unless you have advanced knowledge on how diffusion models work.
FLUX Configurator
Both the FLUX Configurator function and the SD3.5 Configurator function feature a special node able to increase FLUX.1 Dev’s and Stable Diffusion 3.5’s capability to follow the user prompt: CFG Zero Star.
CFG Zero Star is bypassed by default for FLUX Configurator, and it’s enabled by default for SD3.5 Configurator.

NOTICE: CFG Zero Star is compatible with FLUX.1 Dev fine-tuned versions like FLUX.1. Dev Krea.
GI1 Image Generator
The image generation pipeline for the GTP-Image-1 model does not have a Configurator.
The only modifiable parameter, image_quality, is in the GI1 Image Generator function.
WARNING: To use the GI1 Image Generator function, you’ll need both an API key provided by OpenAI and you’ll need to have your organization to be verified by them.
Without verification, a working API key will fail to generate image.
This requirement may change over time. Double-check OpenAI documentation.
Image Stylers
Open Creative Studio supports a type of image styling model called LoRA (Low Ranking Adapter).
LoRAs
The AI community has created hundreds of LoRAs to style image generation. You can download and use them for free in Open Creative Studio.
WARNING: Always check the license terms attached to a LoRA you download. Some of them prohibit commercial use.

Each LoRA is trained specifically for an image generation model. This means that you’ll need to use the FLUX LoRAs function for image generations with FLUX.1 Dev, the SDXL LoRAs function for Stable Diffusion XL, and so on.
Open Creative Studio is preconfigured to use a wide range of LoRAs, organized by focus, for both FLUX.1 Dev and Stable Diffusion XL.
You can download every LoRA preconfigured in Open Creative Studio from this model archive.
The weights of each LoRA featured in Open Creative Studio have been carefully configured after hundreds of hours of testing to generate the best possible image.

Some LoRAs apply their style by simply activating them. However, others also require you to add a trigger word to your user prompt.
To find out what trigger word a LoRA responds to, you can right-click on a LoRA name and choose Show Info.

LoRA Manager
As you add more LoRAs to your Open Creative Studio environment, it will become increasingly difficult to remember which one applies what style.
To simplify the task, Open Creative Studio comes with a LoRA Manager, which automatically builds and organizes a catalog of all your LoRAs.
LoRA Manager is capable of automatically downloading thumbnails for each LoRA, filtering the catalog for specific types of LoRAs, discovering duplicates, and much more.

LoRA Manager can be launched by pressing the L icon in the top bar of the main ComfyUI interface. Once you do that, a secondary browser tab will open.
Image Conditioners
Image conditioners are auxiliary models able to influence the image generation process in various ways.
Some of them can help follow the contours of an existing source image, while others can identify the pose of a human figure in a source image and use that to generate a completely new subject.
NOTICE: To work, image conditioners need the Image Uploader function, the 1st Reference Image function, and/or the 2nd Reference Image function active.
Open Creative Studio supports the following types of image conditioners:
ControlNets
Open Creative Studio supports up to five concurrent ControlNet models for each image generation pipeline.
You can activate one or more of them via the Control Panel:
- Tile
- Canny (with the AnyLine Art preprocessor)
- Depth (with the Metric3D preprocessor)
- Pose (with the DWPose preprocessor)
- Blur [for SD3.5 only]

To increase their efficacy, most ControlNet functions also feature a preprocessor node that can be adjusted according to the type of source images you are using.
If you want to preview how each ControlNet preprocessor will capture the details of your source image, you can use the ControlNet Previews function in the Aux Functions section of Open Creative Studio.

Redux [for FLUX.1 only]
The FLUX Redux functions allow you to use the reference images set in the Image Uploader function for a wide range of use cases.
For example, you can use the FLUX Redux function to generate a variant of a source image:
Or, you can use the FLUX Redux function to merge the character of a reference image into the scene of another reference image:

Or, you can use the FLUX Redux function to merge different concepts coming from multiple reference images into something completely new. And, you can further influence the image generation by activating one or more LoRAs in the FLUX LoRAs function:

Open Creative Studio supports up to three FLUX Redux functions, enabling an unprecedented level of creativity.

NOTICE: The FLUX Redux functions are preconfigured as follows:
- FLUX Redux 1 depends on the 1st Reference Image function.
- FLUX Redux 2 depends on the 2nd Reference Image function.
- FLUX Redux 3 depends on the Image Uploader function.
IPAdapter [for SDXL only]
Similar to the FLUX Redux functions, the SDXL IPAdapter functions allow you to generate variants of the reference image, consistent characters in different poses, or to apply a certain style to new subjects.
The Stable Diffusion XL pipeline features two SDXL IPAdapter functions.
NOTICE: The SDXL IPAdapter functions are preconfigured as follows:
- SDXL IPAdapter 1 depends on the 1st Reference Image function.
- SDXL IPAdapter 2 depends on the 2nd Reference Image function.
The SDXL IPAdapter 2 function is preconfigured as an auxiliary function and has a restricted set of capabilities compared to the SDXL IPAdapter 1 function.
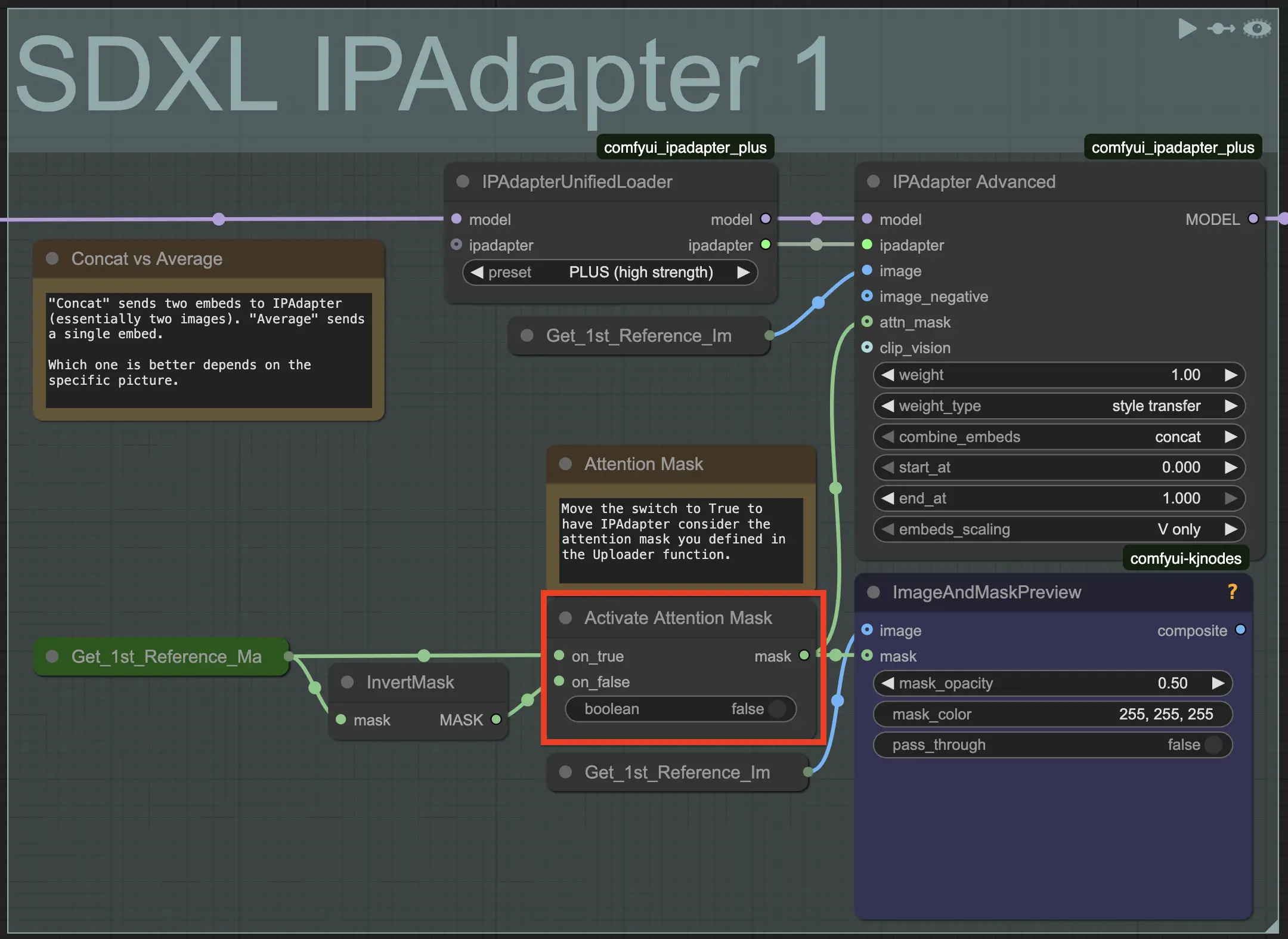
When you work with the SDXL IPAdapter 1 function, Open Creative Studio allows you to specify an attention mask that the IPAdapter model should focus on.
The attention mask must be defined in the 1st Reference Image function, via the ComfyUI Mask Editor.
To force the IPAdapter model to consider the attention mask, you must change the switch in the Activate Attention Mask node, inside the IPAdapter function, from False to True.
For more information on how to use the IPAdapter technique, you are recommended to read this document.
Image Optimizers
Images generated via the Stable Diffusion 1.5 pipeline can be further optimized thanks to three advanced and experimental functions.

Free Lunch (v1 and v2)
The Free Lunch function leverages an optimization technique for Stable Diffusion 1.5 models that improves the quality of the generated images.
For more information, read this research paper.
By default, the function is configured to use the FreeUv1 node. However, you can switch to the FreeUv2 node, which has been configured according to extensive testing performed by the researcher named @seb_caway.
Kohya Deep Shrink
The Kohya Deep Shrink function leverages an optimization technique, developed by @kohya, to generate large Stable Diffusion 1.5 images.
It promises more consistent and faster results when the target image resolution is outside the training dataset compared to alternatives like HighRes Fix.
Perturbed-Attention
The Perturbed-Attention function leverages the optimization technique known as Perturbed-Attention Guidance (PAG).
This technique forces Stable Diffusion 1.5 to follow the user prompt more closely without the need to increase the classifier-free guidance (CFG) scale value and risk of generating burned images.
For more information, read this research paper.
